CGPU天梯图带你攀登算力巅峰,实现技术突破与人生飞跃!

CGPU天梯图:攀登算力巅峰的荆棘与星光
凌晨三点,屏幕幽光映着我发青的脸,那行“CUDA out of memory”的报错第17次跳出来时,我狠狠砸了下键盘——我那服役四年的旧显卡,在加载新模型时又一次彻底崩溃,机箱风扇徒劳地嘶吼,像一头精疲力竭的老牛,拖不动时代这架沉重的犁。
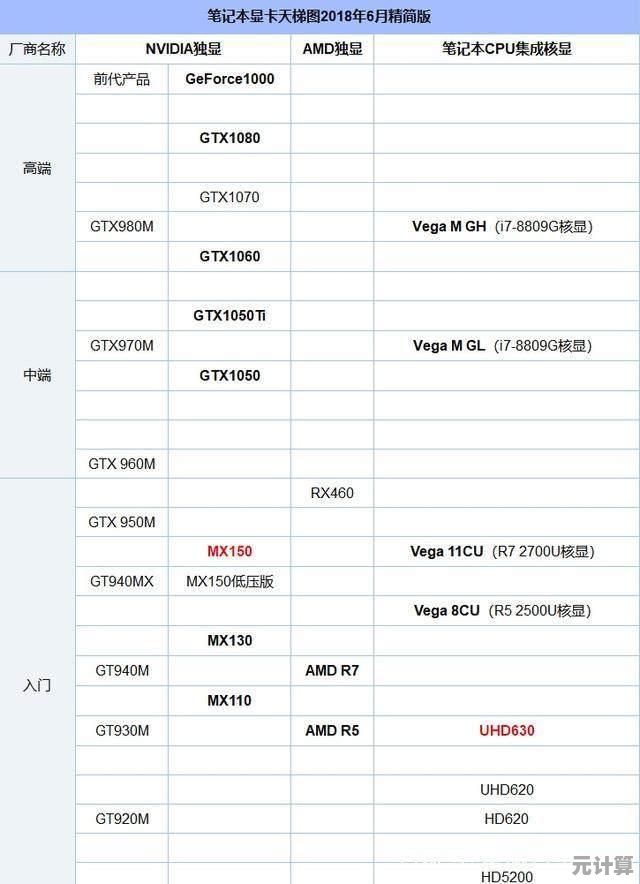
后来偶然看到一张CGPU天梯图,才惊觉自己早被算力洪流甩在了滩涂上,那些陌生的型号代号:H100、MI300X……冷冰冰的字母数字组合背后,是令人眩晕的浮点运算能力,原来我的“老黄牛”,早已被挤到了天梯最底层的阴影里。
算力阶梯上的真实足迹
朋友小陈的初创团队去年咬牙上了A100集群,他描述第一次跑通百亿参数模型时的场景:“像突然推开一扇尘封的窗,数据洪流轰然涌入,过去模糊的关联瞬间清晰可见。”他们用这套算力优化了医疗影像诊断路径,将某类肿瘤的早期识别率提升了近20%,天梯图上那个代表A100的高位坐标,成了他们技术破壁的物理支点。
可攀爬天梯的代价呢?小陈苦笑着给我看他们机房的电费单——那数字灼痛眼睛,更残酷的是,当H100横空出世,他们刚搭建的“巅峰”瞬间矮了半截,算力竞赛如同追逐地平线,永远在接近,却难言真正抵达。

我的“非典型”攀登
预算有限的我,最终选了天梯中游的某张卡,没有一步登天的狂喜,却意外收获了另一种自由:不必再为每个CUDA核心锱铢必较,反而逼迫自己沉入算法优化的深海,一次为减少模型冗余结构,我反复调整了47次参数组合,当最终在“次旗舰”显卡上跑出接近顶级卡的效率时,那种亲手“拧干数据海绵”的满足感,远胜于粗暴堆砌硬件带来的短暂虚荣。
巅峰之下,冷思灼见

天梯图诚然是张实用的寻路图,但若只仰头盯着塔尖的光环,极易坠入迷思:
- 算力通胀的焦虑陷阱: 新卡发布周期越来越短,追新如同夸父逐日,我曾陷入这种焦虑,直到发现某开源社区用几年前的旧卡集群,通过极致优化依然支撑着前沿研究。
- “唯算力论”的窄门: 见过太多团队将资源孤注一掷押在硬件上,却忽视了数据清洗、算法创新或工程化落地的“软实力”,算力是引擎,但决定方向的终究是手握方向盘的人。
- 生态的隐形阶梯: 软件栈适配、框架支持、社区资源……这些构成算力落地的“暗梯”,某国产GPU纸面参数亮眼,却因生态薄弱,在实际部署中举步维艰,在天梯图上的高位显得摇摇欲坠。
攀登算力之峰,天梯图是实用的向导,却非唯一的真理,真正的“巅峰体验”,或许不在于触摸最顶端的那个坐标点,而在于每一次利用手中算力,撬动认知边界的那个决定性瞬间——无论这算力来自天梯的哪一层。
当我的“次旗舰”显卡终于流畅跑起新模型,风扇声变得平稳如呼吸,屏幕上的loss曲线优雅下降,那一刻的平静喜悦,远胜于对某个虚幻顶点的空洞仰望,算力天梯永无尽头,但每一次用技术真切解决问题的时刻,都是攀登者独有的、真实的“人生海拔”。
后记:深夜跑完最后一个epoch,咖啡凉透,窗外已有晨光,工具是死的,人是活的——在算力洪流中保持清醒,比单纯登顶更需要勇气。
本文由苦芷烟于2025-09-28发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://max.xlisi.cn/wenda/42806.html
![[QQ三国]烽火连城,热血征战成就霸业传奇!](http://max.xlisi.cn/zb_users/upload/2025/09/20250928224921175907096142884.jpg)