深入内存读取天梯图:从基础原理到高速缓存的层次化探索

从基础原理到高速缓存的层次化探索
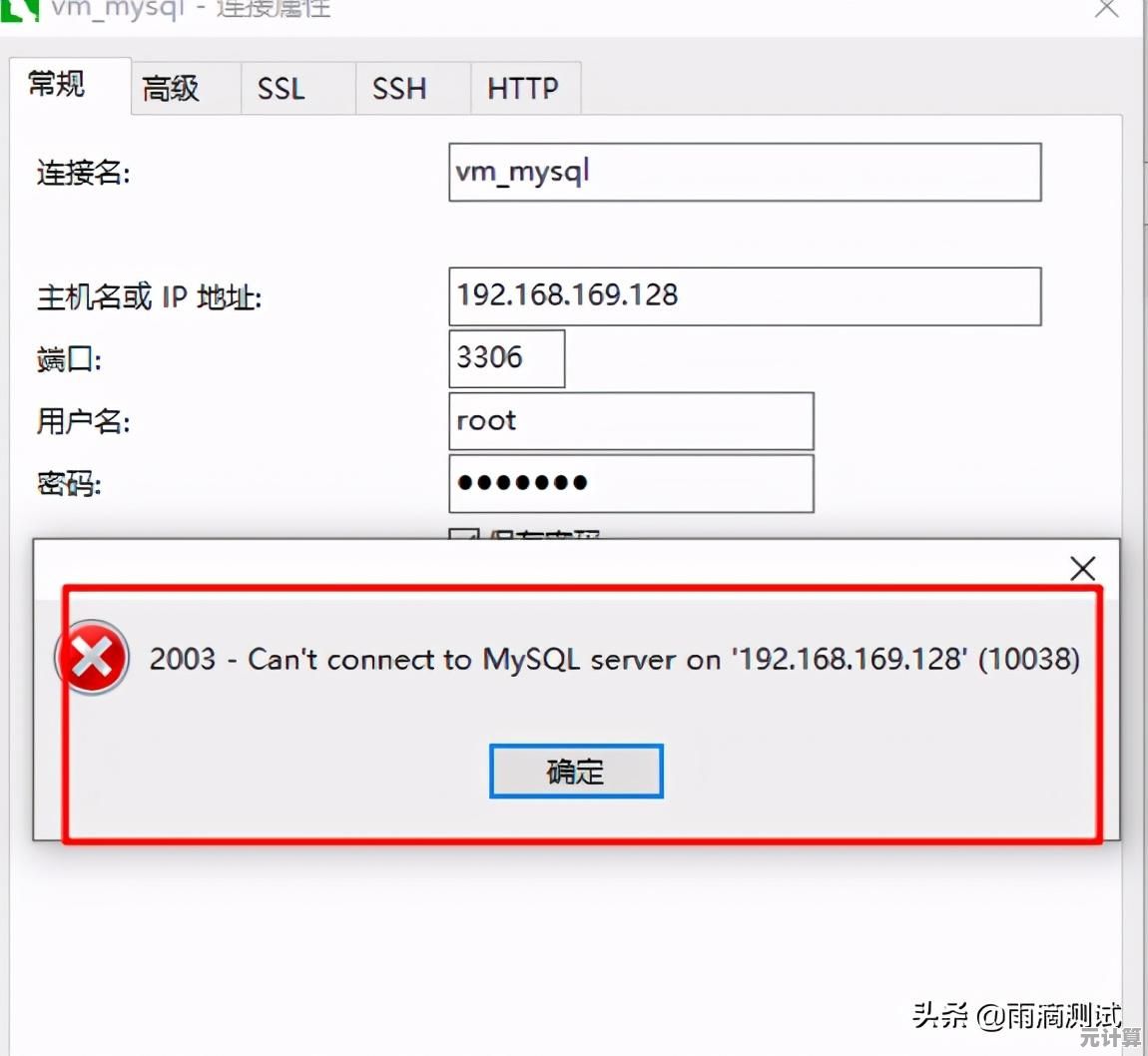
记得我第一次拆开那台老旧的台式机时,面对主板上那些细小的黑色芯片和错综复杂的线路,心里既兴奋又有点懵,那时候我根本分不清内存条和缓存的区别,甚至觉得“内存”就是电脑里那个能存照片和文件的地方,后来才知道,原来“内存读取”这件事,背后藏着一整个微观宇宙般的层次结构——从寄存器到L1、L2、L3缓存,再到主内存和硬盘,像是一层层递进的天梯,每一步的延迟和带宽都在暗地里较劲。
其实内存读取的本质很简单:CPU要干活,总得有个地方放指令和数据吧?但CPU跑得太快了,而内存慢得像老牛拉车——这之间的速度差就成了问题,解决办法就是搞个“中间商赚差价”:在CPU和主内存之间插几层高速缓存(Cache),让常用数据提前蹲在离CPU更近的地方,但这事儿说起来轻松,做起来可太复杂了。
举个例子,有一次我写代码做图像处理,循环遍历一个超大数组,一开始傻乎乎地直接怼,结果跑得比蜗牛还慢,后来我把数据块按缓存行(Cache Line)大小重新排列,命中率唰就上去了——速度直接翻倍,那时候我才真切体会到,缓存命中(Cache Hit)和缓存未命中(Cache Miss)之间的性能差距,简直像是开跑车和骑自行车的区别。
缓存的设计其实特别“人性化”,比如局部性原理:时间局部性(最近用的数据很可能马上再用)和空间局部性(用了某个地址的数据,很可能顺便用它旁边的数据),这就像你做饭时不会每次切菜都跑回仓库拿刀,而是先把刀具摆灶台边上——CPU也是这么“偷懒”的。

但缓存也不是万能的,有一次我调试一个多线程程序,明明逻辑没问题,却偶尔会冒出诡异的结果,熬到凌晨三点才发现是伪共享(False Sharing)在捣鬼——两个核心的缓存行意外重叠,导致互相无效化数据,那时候一边骂架构设计师太鸡贼,一边又佩服这种细节居然能逼疯人。
再说回内存天梯的层次,L1缓存快得飞起,但容量小得像钱包里的零钱;L3缓存大了一些,但延迟也高了;主内存嘛,简直就是仓库和灶台之间的距离,有时候我觉得这像极了现实生活中的物流系统:快递站(L1)、中转仓(L2)、区域中心(L3)、总仓库(内存)——优化效率的关键就是减少搬运次数。

现在很多厂商拼命堆L3缓存容量,比如游戏CPU塞进超大的L3,帧数居然真能稳一截,但缓存越大越好吗?未必,物理限制、功耗、成本都是问题,有时候我觉得这就像装修房子:柜子多了能收纳,但走道窄了反而碍事。
说到底,内存层次设计是一场妥协艺术,速度、容量、成本、功耗——每个因素都在打架,我们总想追求完美平衡,但完美本身可能就是个坑,就像我那个总在纠结“要不要再加条内存”的朋友,最后发现瓶颈其实在硬盘IO上……
(写到这里突然想起,当年AMD的Zen架构靠堆缓存逆袭Intel,真是经典案例,不过具体细节记不清了,回头得再查查资料……)
内存天梯的每一阶都有它的脾气,有时候你觉得底层原理枯燥,但真钻进去,会发现它们比小说还精彩——毕竟,这是数字世界里的物理法则在跳舞啊。
本文由冠烨华于2025-10-02发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://max.xlisi.cn/wenda/49565.html