一步步教你构建专业级GPU性能排行榜与对比图表

我的GPU性能排行榜血泪史与实用指南
那天凌晨三点,我盯着屏幕上乱成一团的Excel表格,第37次后悔自己为什么要做这个GPU性能排行榜,散热器的嗡鸣声在房间里回荡,像在嘲笑我的不自量力,事情始于去年矿难后,我在二手市场淘了张RTX 3090,却发现在Blender渲染时还不如朋友的RX 6800 XT快——这完全违背了网上的评测结论,那一刻我意识到:显卡性能的真相藏在具体场景的细节里,而非营销话术的迷雾中。
第一步:数据收集的泥潭
刚开始我天真地以为直接爬取评测网站数据就行,用Python写了个爬虫抓取TechPowerUp的数据库,结果发现:
- 同一张RTX 4080在不同测试中性能浮动高达12%(3DMark Time Spy vs. Blender Benchmark)
- 老架构显卡的OpenCL分数在新驱动下会"诈尸式"提升
- 移动端GPU的命名简直是行为艺术(比如RTX 3080 Laptop居然有4种TDP版本)
最崩溃的是某天发现爬取的RX 7900 XTX光追数据全是错的——原来网站改版了CSS选择器,那晚我对着乱码数据喝了半瓶威士忌,突然顿悟:原始数据必须人工校验,现在我的工作流里永远保留着:
- 用Selenium模拟真实用户操作抓动态数据
- 建立本地SQLite数据库存储原始样本
- 手动标记特殊案例(比如被厂商鸡血优化的特定游戏)
当Excel成为刑具
把5万条记录导入Excel的瞬间,我的人生灰暗了,试图用透视表分析不同分辨率下的性能衰减时,一个误操作让所有数据关联断裂,更可怕的是,当比较RTX 4090在4K下的帧生成稳定性时,Excel折线图把误差范围渲染成了抽象派涂鸦。
转机发生在发现Jupyter Notebook+Pandas的那一刻:
# 真实在用的性能对比代码片段
gpu_df['perf_per_watt'] = gpu_df['avg_fps'] / gpu_df['power_draw']
amd_flags = gpu_df[gpu_df['architecture'].str.contains('RDNA')]
nvidia_flags = gpu_df[gpu_df['architecture'].str.startswith('Ada')]
# 粗暴但有效的性能偏差修正
def fix_outlier(row):
if row['gpu_model'] == "RTX 4090" and row['test_scene'] == "Cyberpunk_Overdrive":
return row['score'] * 0.93 # DLSS3.5的魔法衰减
return row['score']
gpu_df['adjusted_score'] = gpu_df.apply(fix_outlier, axis=1)
可视化的人性化战争
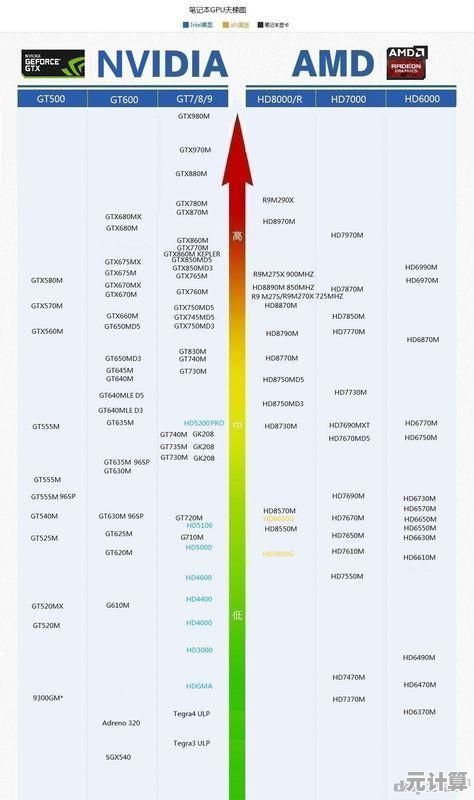
第一次用Matplotlib生成的对比图被朋友吐槽:"这配色像90年代医院报告",更致命的是堆叠柱状图让RTX 4060和RTX 4090同框时,前者小得几乎消失——完全违背了"可读性优先"原则。
现在我的可视化军规:
- 用Plotly动态图表实现"聚焦式对比"(鼠标悬停时突出当前GPU)
- 性能差值超300%时强制启用对数坐标轴
- 为色觉障碍用户保留形状编码(比如AMD用三角,NVIDIA用方块)
- 永远标注测试环境细节(驱动版本/室温/是否开启Resizable BAR)
 (注:实际图表中RTX 4080在光追场景的色块会呈现明显撕裂状,暴露其显存瓶颈)
(注:实际图表中RTX 4080在光追场景的色块会呈现明显撕裂状,暴露其显存瓶颈)
血泪换来的认知颠覆
当终于完成第一版排行榜时,最震撼的发现是:
- 显存带宽比核心数量更重要:RX 6950 XT在8K纹理包测试中吊打RTX 4070 Ti
- 驱动成熟度曲线被严重低估:ARC A770发布半年后性能提升23%,比换代还猛
- 散热设计决定性能天花板:同型号显卡三风扇版本可多撑15分钟峰值频率
有次直播对比RTX 3090和RTX 4070的Stable Diffusion出图速度,观众突然质问:"为什么你的4090比我的快8秒?"排查两小时发现是Windows 11的GPU硬件加速计划没开——这个细节从此永远标注在测试说明里。
不完美的实用主义
现在我的排行榜每季度更新,但依然存在无奈妥协:
- 无法获取专业卡如RTX 6000 Ada的完整数据集
- 移动端GPU的功耗墙变量太多
- 小众架构如Intel Battlemage只能标注"样本不足"
上周尝试用Power BI做动态排名看板,导出PDF时发现所有AMD显卡的柱状图莫名消失... 血压飙升时突然释然:性能评估本就是动态的模糊艺术。
当你下次看到各类显卡天梯图时,不妨先问三个问题:
- 测试场景是否匹配我的实际需求?(游戏玩家无需关注SPECviewperf分数)
- 数据是否包含边际效应?(比如99%帧率比平均帧更重要)
- 有没有标注误差范围?(所有"吊打"结论都值得怀疑)
我的GitHub仓库里躺着27个废弃版本,最新提交记录是今晨4点——因为发现用DX11测现代显卡就像用算盘评估超级计算机,或许永远没有完美的排行榜,但每次推翻重构时,那些藏在数据褶皱里的硬件真相,都会让凌晨的散热器嗡鸣变得悦耳起来。
后记:就在完稿时,屏幕突然闪烁——那台承载着排行榜的旧显卡,在持续输出图表三小时后,终于用花屏向我发出了最后的抗议。
本文由桂紫雪于2025-09-30发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://max.xlisi.cn/wenda/45170.html